Methodology
for the migration of bibliographic data between automation software:
from ECLAC to MARC
RESUMEN
En la actualidad existen aun muchas bases de datos bibliograficas
disenadas en WinIsis sobre formato de intercambio de informacion CEPAL;
sin embargo, la tendencia de los nuevos software de gestion
de unidades
de informacion es la utilizacion del formato MARC21, con el
inconveniente de que ambos formatos son incompatibles entre si. Por
eso, el presente documento ofrece una guia para migrar del formato
CEPAL al formato MARC21 utilizando una tabla de equivalencias de campos
en una FST de exportacion. Se construyo, ademas, una base de datos
intermedia en WinIsis donde se vaciaron los datos convertidos.
Posteriormente, se describe el proceso de conversion de un archivo de
salida ISO2709 a un archivo MARC puro, que puede ser cargado desde
cualquier sistema de gestion de unidades de informacion de ultima
generacion. Tambin, se describe el proceso de depuracion del mismo
utilizando el programa MarcEdit y se realiza un ejemplo de la carga
final en la aplicacion de automatizacion EspaBiblio 3.2. Se concluye
que todo proceso de migracion debe responder a un proyecto previamente
definido y la importancia de realizar la depuracion para garantizar la
pureza de los datos.
Palabras clave: automatizacion de bibliotecas, migracion de datos, bases de datos, bases de datos textuales
ABSTRACT
At present there are still many bibliographic databases designed in
WinIsis on ECLAC exchange format information, however, the trend of new
software
management information units is the use of MARC21 format, with
the drawback that both formats are incompatible with each other. This
document provides guidance for migrating from ECLAC format to MARC21
format using a conversion table of fields in a FST export. It also
built an intermediate database in which the converted data WinIsis
emptied. Subsequently, the process of converting an output file ISO2709
to a file pure MARC, which can be loaded from any system of information
management units described generation. It also describes the process of
debugging the same program using the MARCEdit and an example of the
final charge is made in the application of automation EspaBiblio 3.2.
It is concluded that the process of migration to respond to a
previously defined project and the importance of debugging to ensure
the purity of the data.
Keywords: library automation, data migration, databases, textual databases
Fecha de recibido: 31 de marzo del 2014
Fecha de
aprobado: 12 de mayo del 2014
Fecha de corregido: 03 de junio del 2014
1. INTRODUCCION
Hasta hace muy poco tiempo, el software
de automatizacion de catalogos
WinIsis se ha utilizado como estandar para el manejo de la descripcion
bibliografica en muchas unidades de informacion. Por su parte y para el
caso concreto de Amrica Latina, la Comision Economica para Amrica
Latina y el Caribe (CEPAL) tuvo en la dcada de los 80 y 90 del siglo
pasado una participacion sumamente activa en el ambito de la
distribucion del WinIsis y el intercambio de informacion bibliografica.
En primera instancia, la CEPAL desarrollo su formato de intercambio de informacion (conocido como formato CEPAL) para uso interno. Sin embargo, se detecto la problematica surgida por el diseno libre y desordenado de bases de datos bibliograficas sin formato alguno, lo cual generaba incompatibilidades en el intercambio de informacion. Por tal motivo y como apoyo a las bibliotecas de Amrica Latina, se distribuyo el formato CEPAL junto con el paquete WinIsis, por lo cual se utilizo de manera extensiva (Ugobono, 2011).
No obstante, debido a los cambios y demandas actuales de los usuarios, ahora se requieren sistemas de automatizacion modernos, agiles, modulares y con posibilidades de crecimiento bajo estandares internacionales. Por lo tanto, el WinIsis ya ha dejado de ser una opcion. De hecho, hay que recordar que WinIsis es una sistema de primer nivel de automatizacion (Chinchilla, 2011), no es multiplataforma y su desarrollo se detuvo en la version 1.5 (solamente corre sobre las antiguas versiones de Windows NT/2000/XP). Esto hace necesario el evaluar otras alternativas para los nuevos proyectos de automatizacion y para el desarrollo tecnologico de las unidades de informacion ya automatizadas.
Sin bien es cierto que el formato CEPAL es aun de uso extensivo, los nuevos sistemas de automatizacion integral de unidades de informacion han apostado por el formato MARC (MAchine-Readable Cataloging), desarrollado por la Biblioteca del Congreso de los Estados Unidos de Amrica y que ya va por la version 21. Con este panorama nos enfrentamos al hecho de que si deseamos migrar a una nueva plataforma informatica, es necesario comenzar por migrar de formato de intercambio de informacion.
Aunque, algunos sistemas como SIABUC� o aplicaciones basadas en WinIsis como ABCD3 pueden cargar archivos tipo ISO 2709, los archivos MRC pueden ser cargados por cualquier aplicacion de automatizacion de unidades de informacion. Para ofrecer un ejemplo de este ultimo punto, se ejemplifica dicha carga utilizando el programa EspaBiblio 3.24.
Entonces, el objetivo de este documento es atender la problematica descrita, proponiendo una metodologia de migracion. En primera instancia, se explica como realizar la migracion de datos del formato CEPAL al MARC utilizando una tabla de equivalencias. En segunda, se explica como utilizar la aplicacion MarcEdit 5.95 para transformar el archivo ISO 27096 generado por el proceso de exportacion de WinIsis en un archivo tipo MRC (MARC puro) y depurarlo. Una vez limpio, este archivo puede ser cargado por el sistema de automatizacion de nuestra eleccion.
En primera instancia, la CEPAL desarrollo su formato de intercambio de informacion (conocido como formato CEPAL) para uso interno. Sin embargo, se detecto la problematica surgida por el diseno libre y desordenado de bases de datos bibliograficas sin formato alguno, lo cual generaba incompatibilidades en el intercambio de informacion. Por tal motivo y como apoyo a las bibliotecas de Amrica Latina, se distribuyo el formato CEPAL junto con el paquete WinIsis, por lo cual se utilizo de manera extensiva (Ugobono, 2011).
No obstante, debido a los cambios y demandas actuales de los usuarios, ahora se requieren sistemas de automatizacion modernos, agiles, modulares y con posibilidades de crecimiento bajo estandares internacionales. Por lo tanto, el WinIsis ya ha dejado de ser una opcion. De hecho, hay que recordar que WinIsis es una sistema de primer nivel de automatizacion (Chinchilla, 2011), no es multiplataforma y su desarrollo se detuvo en la version 1.5 (solamente corre sobre las antiguas versiones de Windows NT/2000/XP). Esto hace necesario el evaluar otras alternativas para los nuevos proyectos de automatizacion y para el desarrollo tecnologico de las unidades de informacion ya automatizadas.
Sin bien es cierto que el formato CEPAL es aun de uso extensivo, los nuevos sistemas de automatizacion integral de unidades de informacion han apostado por el formato MARC (MAchine-Readable Cataloging), desarrollado por la Biblioteca del Congreso de los Estados Unidos de Amrica y que ya va por la version 21. Con este panorama nos enfrentamos al hecho de que si deseamos migrar a una nueva plataforma informatica, es necesario comenzar por migrar de formato de intercambio de informacion.
Aunque, algunos sistemas como SIABUC� o aplicaciones basadas en WinIsis como ABCD3 pueden cargar archivos tipo ISO 2709, los archivos MRC pueden ser cargados por cualquier aplicacion de automatizacion de unidades de informacion. Para ofrecer un ejemplo de este ultimo punto, se ejemplifica dicha carga utilizando el programa EspaBiblio 3.24.
Entonces, el objetivo de este documento es atender la problematica descrita, proponiendo una metodologia de migracion. En primera instancia, se explica como realizar la migracion de datos del formato CEPAL al MARC utilizando una tabla de equivalencias. En segunda, se explica como utilizar la aplicacion MarcEdit 5.95 para transformar el archivo ISO 27096 generado por el proceso de exportacion de WinIsis en un archivo tipo MRC (MARC puro) y depurarlo. Una vez limpio, este archivo puede ser cargado por el sistema de automatizacion de nuestra eleccion.
2. PROCESO DE MIGRACION
Se debe recordar que al momento de disenar una bases de datos en WinIsis, deben definirse cuatro archivos de trabajo:
1. Tabla de definicion de
campos (FDT): aqui se
muestra el numero y nombre de cada uno de los campos sobre
los
cuales se trabajara, asi como una serie de variables para cada campo, como la
definicion de los subcampos, si son repetibles o no y si tienen
un patron definido para el ingreso de la informacion. Es aqui donde se
define el formato de intercambio sobre el que se
trabajara.
2. Hoja de entrada de datos (FMT): se
construye la
hoja sobre la cual se digitaran los datos bibliograficos que seran
ingresados a la base de datos.
3. Formato de visualizacion (PFT): en
este archivo se
disena la forma como se veran los datos en pantalla o impresos.
4. Tabla se seleccion de datos (FST): en
este archivo
se indica cuales seran los campos que serviran como puntos de entrada a
los registros.
Una vez disenada la base de datos, se generan de forma automaticas
varios archivos, dentro de los cuales se destacan los siguientes:
- Archivo Maestro (MST): archivo que contiene todos los registros ingresados a la base de datos.
- Archivo Invertido o Diccionario de Datos (IFP): archivo de punteros generado por los campos senalados en el FST previamente definido.
Ademas, WinIsis controla cada uno de los registros asignando un numero
consecutivo a cada uno de ellos, denominado Numero Maestro (MFN). Es
importante especificar que este numero no funciona como una llave
primaria de cada registro, es simplemente un numero consecutivo que se
reacomodara cada vez que se borren e ingresen nuevos registros.
Todos los archivos mencionados son almacenados en el directorio DATA de WinIsis. La estructura de almacenamiento de todo el programa es la siguiente:
Todos los archivos mencionados son almacenados en el directorio DATA de WinIsis. La estructura de almacenamiento de todo el programa es la siguiente:
En el directorio PROG se encuentran los programas ejecutables, en MENU
todos los menus del sistema y en el directorio WORK se almacenan todas
las salidas, como impresiones, exportaciones y demas. Este ultimo
directorio es muy importante para el proceso que se describira mas
adelante.
2.1 Proceso de conversion de CEPAL a MARC en WinIsis
Para este proceso, se utilizan dos bases de datos desarrolladas en WinIsis: la primera con los campos mas utilizados del formato CEPAL7 y la segunda con los campos equivalentes en el formato MARC. Se construye, ademas, una FST con las equivalencias de campos y que funcionara como puente entre ambas bases. Si la base de datos a migrar tuviese mas campos, es posible ampliar la tabla de equivalencias.
La primera base de datos tiene la FDT tal y como se muestra en la tabla siguiente. Ademas, se debe tener presente que el formato CEPAL no utiliza subcampos.
2.1 Proceso de conversion de CEPAL a MARC en WinIsis
Para este proceso, se utilizan dos bases de datos desarrolladas en WinIsis: la primera con los campos mas utilizados del formato CEPAL7 y la segunda con los campos equivalentes en el formato MARC. Se construye, ademas, una FST con las equivalencias de campos y que funcionara como puente entre ambas bases. Si la base de datos a migrar tuviese mas campos, es posible ampliar la tabla de equivalencias.
La primera base de datos tiene la FDT tal y como se muestra en la tabla siguiente. Ademas, se debe tener presente que el formato CEPAL no utiliza subcampos.
Por su parte, la base de datos sobre la que se descargaran los datos a
migrar se disena utilizando MARC. Tambin, debe tenerse en cuenta que
toda migracion es propensa a la prdida de datos si no existe el campo
o subcampo equivalente en el formato al que se va a migrar. Por eso, la
Tabla 2 muestra la estructura de campos.
Se podra notar que no se incluyen algunos subcampos, como el ^d del
campo 100 o los subcamos adicionales del campo 245, esto debido a que
no hay un campo equivalente en la Tabla 1. Se insiste en que toda
migracion es propensa a la prdida de datos.
Revisadas ambas estructuras, se procede a construir la tabla de equivalencias. Para ello, se desarrolla una FST con la siguiente estructura:
Esta FST presenta las siguientes caracteristicas:
- En la columna de la izquierda contiene el identificador de campo de entrada MARC donde se almacenaran los datos.
- En la columna central se muestra la tcnica de indizacion. En el caso concreto debe ser tipo 0, que seleccionara el contenido completo del campo.
- En la columna de la derecha se senala el formato de extraccion que contiene los indicadores de cada campo, el campo de salida en formato CEPAL que contiene los datos a transferir y los subcampos MARC.
La funcion de los indicadores la describe la Biblioteca del Congreso de los Estados Unidos:
Indicadores:
De las dos posiciones de caracteres
que le siguen a cada
etiqueta (con excepcion de los campos 001 al 009), una o ambas pueden
estar ocupadas por indicadores. En
algunos campos se
utiliza unicamente
la primera o la segunda posicion; en otros campos se usan las dos, y en
algunos como el 020 y el 300 no se usa ninguna. Cuando una posicion de
indicador no se usa se dice que "no esta definida", y dicha posicion se
deja en blanco. Por regla convencional se representa a los espacios
dejados en blanco en los indicadores (no definidos) mediante el simbolo "#" (Biblioteca
del Congreso, 2003, parr 31.).
Los indicadores son dos digitos que van del 0 al 9 y no se leen en forma conjunta sino en forma individual, debido a que son dos numeros individuales. Como se muestra en el ejemplo siguiente (Figura 1), el numero 245 corresponde al campo de titulo, el 13 representa los indicadores (Biblioteca del Congreso, 2003).
El primer indicador es el 1, el cual senala que el titulo de la obra es
un asiento secundario; si fuese 0 significa que el documento no tiene
autor o son mas de 3 y el titulo entra como punto de acceso principal.
El segundo indicador es 3, que le senala a la base de datos donde debe iniciar la alfabetizacion del titulo, es decir, si es un 3 debe ubicarse en el cuarto campo del titulo para el acomodo alfabtico del mismo, estos 3 campos incluyen espacios en blanco para que la computadora no tome en cuenta dichos caracteres en el proceso de ordenamiento alfabtico. En el titulo La cordillera andina el valor del segundo indicador es 3, de manera que los primeros tres caracteres (la "L" la "a" y el espacio) seran ignorados y el titulo sera alfabetizado bajo la letra “c” de "cordillera andina".
Es importante recordar que ninguna migracion es completamente efectiva y siempre habra algun porcentaje de prdida de datos. Esto se debe a que, por su propia naturaleza, no existe uniformidad en la informacion bibliografica ingresada y no es posible prever todas las posibles combinaciones que pudiesen presentarse. Esto se explica en el siguiente ejemplo:
El segundo indicador es 3, que le senala a la base de datos donde debe iniciar la alfabetizacion del titulo, es decir, si es un 3 debe ubicarse en el cuarto campo del titulo para el acomodo alfabtico del mismo, estos 3 campos incluyen espacios en blanco para que la computadora no tome en cuenta dichos caracteres en el proceso de ordenamiento alfabtico. En el titulo La cordillera andina el valor del segundo indicador es 3, de manera que los primeros tres caracteres (la "L" la "a" y el espacio) seran ignorados y el titulo sera alfabetizado bajo la letra “c” de "cordillera andina".
Es importante recordar que ninguna migracion es completamente efectiva y siempre habra algun porcentaje de prdida de datos. Esto se debe a que, por su propia naturaleza, no existe uniformidad en la informacion bibliografica ingresada y no es posible prever todas las posibles combinaciones que pudiesen presentarse. Esto se explica en el siguiente ejemplo:
Etiqueta
245
Tecnica
0
Formato
"10^a"v60,v75
El
indicador 1 se utiliza cuando el titulo tiene entrada secundaria, es
decir cuando hay un autor responsable del documento, pero si hay
documentos que entran por titulo, entonces el indicador deberia ser
0 . El segundo indicador es 0, el cual se utiliza cuando el titulo
no tiene articulos, pero siempre habran algunos que si los tienen.
Por
su parte, el subcampo ^a es para el titulo propiamente dicho. Sin
embargo es necesario contemplar el subcampo ^b para el resto del
titulo, el ^c para la mencion de responsabilidad y el ^h para la
Designacion General del Material (DGM). Si la base de datos original
tiene estos subcampos, entonces es necesario agregarlos en la tabla
de equivalencias.
Una vez construida la FST de exportacion,
la que para este ejercicio
llamaremos MIGRA.FST, se procede a exportar la base de datos en CEPAL.
El archivo de salida, el cual es generado por WinIsis utilizando el
estandar ISO2709 como se menciono con antelacion, se denominara
MIGRA.ISO (Ver Figura 2). Los parametros que se deben mostrar en la
ventana de dialogo de exportacion son los siguientes:• Nombre del archivo ISO de salida: MIGRA.ISO
• Intervalo desde 1 hasta 999999 (toda la base de datos)
• Longitud de linea de salida (en algunas versiones aparece Caracteres por linea): 0
• Direccion fisica de la FST de reformateo: C:\WINISIS\DATA\MIGRA.FST
Una vez ejecutada la exportacion, se generara el archivo MIGRA.ISO en
el directorio WORK de WinIsis.
Ahora es necesario salir de la base de datos de CEPAL e ingresar a la base de datos disenada sobre MARC senalada en la Tabla 3. Una vez dentro se procede a importar el archivo ISO generado con antelacion. En la ventana de dialogo de importacion es necesario demostrar lo siguiente:
Ahora es necesario salir de la base de datos de CEPAL e ingresar a la base de datos disenada sobre MARC senalada en la Tabla 3. Una vez dentro se procede a importar el archivo ISO generado con antelacion. En la ventana de dialogo de importacion es necesario demostrar lo siguiente:
- Archivo ISO de entrada: MIGRA.ISO
- Primer MFN a ser asignado: 1
- En las opciones de importacion que se ofrecen, se debe seleccionar CARGAR. Con esto se asegura que se eliminara cualquier registro previo existente.
- Longitud de linea de entrada (o caracteres por linea): 0
Una vez realizado el proceso, se pueden verificar los registros ingresados a la base y posteriormente se procede a exportar la base de datos completa una vez mas. En esta oportunidad en la ventana de dialogo de exportacion se indica el nuevo nombre del archivo de salida (para este ejercicio sera MARC.ISO) y los caracteres por linea nuevamente seran 0 y ya no es necesario senalar la FST de reformateo. Este proceso generara el archivo indicado y lo almacenara nuevamente en el directorio WORK.
2.2 Depuracion de datos utilizando MarcEdit
Los datos almacenados en el archivo ISO generado en el proceso anterior siempre tendran algunas inconsistencias y errores, sobre todo con el manejo de tildes y demas signos propios, en este ejemplo concreto, del idioma espanol. Por tal motivo, es necesario realizar alguna limpieza directamente sobre cada uno de los registros contenidos en el archivo de salida. Para depurar dichos datos se utiliza MarcEdit8, un programa multiplataforma de acceso libre para editar y corregir registros MARC.
Como primer paso, debemos transformar el archivo ISO en un archivo MRC.
Para ello, una vez abierto el MarcEdit, se ingresa al menu Add-ins y se
selecciona la opcion CDS-Isis.iso
–
Marc Translation. Se selecciona el
archivo de entrada (marc.iso) que se encuentra en la carpeta WORK de
WinIsis y se muestra el nombre del archivo de salida. Este ejercicio se
llamara openbiblio.mrc y se guardara en c:\winisis\work\ Una vez
senalados los archivos correspondientes, se presiona el boton OK, la
pantalla “parpadea” una vez y se procede a presionar el boton
Close (Figura
5).
La accion anterior ha generado un archivo tipo MRC que es necesario
depurar. Para ello, se abre el Marc Tools para convertirlo en a la
extension MRK con la finalidad de editarlo y depurarlo como se muestra
en la Figura 6.
Una vez convertido el archivo con la extension mrk, se abre con MarcEditor, que consiste en un editor de texto plano. En dicho editor se selecciona el menu File y la opcion Open. Se busca el archivo openbiblio.mrk generado en el paso anterior y se abre para proceder a su limpieza (Figura 7).
Una vez convertido el archivo con la extension mrk, se abre con MarcEditor, que consiste en un editor de texto plano. En dicho editor se selecciona el menu File y la opcion Open. Se busca el archivo openbiblio.mrk generado en el paso anterior y se abre para proceder a su limpieza (Figura 7).
Este proceso requiere de mucho cuidado y dedicacion. Por lo tanto, es
importante tener presentes los caracteres basicos que deberan ser
tomados en cuenta para su respectiva recuperacion, que no fueron
reconocidos en el proceso de conversion y que se sustituyeron por
grupos de caracteres encerrados en llaves {}. A manera de ejemplo
tendriamos los siguientes:
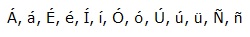
Es importante indicar que, si se tuviesen registros en otros idiomas diferentes del ingles, se deben incluir los caracteres propios de dicho idioma. Despus de una rapida revision por los primeros registros, se puede ir formando una tabla de conversion de la siguiente forma:
Es importante indicar que, si se tuviesen registros en otros idiomas diferentes del ingles, se deben incluir los caracteres propios de dicho idioma. Despus de una rapida revision por los primeros registros, se puede ir formando una tabla de conversion de la siguiente forma:
Una vez identificadas las series de caracteres a convertir, se
selecciona en el menu Edit
la
opcion Replace, se indica la serie de
caracteres a convertir en la primera linea de dialogo, el caracter que
se desea recuperar en la segunda linea de dialogo y se selecciona
Replace All.
Se presiona Acept
y el editor se encargara de
realizar las
conversiones necesarias a lo largo del documento.
Hay que recordar que es necesario salvar el documento cada vez que se
realiza una conversion, con el fin de evitar prdidas de trabajo por
posibles imprevistos. Una vez finalizada la revision es necesario volver a
generar el archivo mrc. Para ello se selecciona en el menu File la
opcion Compile file into MARC, se selecciona el archivo openbiblio.mrc
y se salva. El sistema indicara si se desea reeemplazar el archivo, se
indica que si. Al final de la labor de limpieza tendremos un
archivo MARC listo para ser cargado por cualquier sistema de
automatizacion de unidades de informacion.
2.3 Carga de datos en un sistema de automatizacion de unidades de informacion
Para ejemplificar la carga de un archivo MARC en un sistema de
automatizacion de unidades de informacion, se utilizara EspaBiblio 3.29.
Se escogio dicho programa por ser un software de tercer
nivel de
automatizacion (Chinchilla
y Fernandez, 2012), pero de complejidad
mediana (Fernandez, 2013), lo cual facilita la ejecucion y comprension
del ejemplo.
Como primer paso, es necesario ingresar al sistema y autenticarse como usuario administrador, a fin de tener los permisos necesarios para poder realizar los cambios pertinentes. Posteriormente se debe revisar que los campos contenidos en la hoja de trabajo book sean los mismos que contiene visibles la tabla 3, a fin de verificar la correcta descarga de los datos. Para ello basta con ingresar al menu Catalogacion y seleccionar Nuevo material. Por defecto se encuentra seleccionada la hoja de trabajo book, correspondiente a libros.
Como primer paso, es necesario ingresar al sistema y autenticarse como usuario administrador, a fin de tener los permisos necesarios para poder realizar los cambios pertinentes. Posteriormente se debe revisar que los campos contenidos en la hoja de trabajo book sean los mismos que contiene visibles la tabla 3, a fin de verificar la correcta descarga de los datos. Para ello basta con ingresar al menu Catalogacion y seleccionar Nuevo material. Por defecto se encuentra seleccionada la hoja de trabajo book, correspondiente a libros.
Si falta algun campo, es necesario agregarlo. Para hacerlo se siguen
los siguientes pasos:
1. Dentro del menu Administracion
se selecciona Tipos
de Material, donde apareceran las distintas hojas de
trabajo.
2. Se selecciona Campos
Marc en la linea book,
como
se muestra en la siguiente figura:
3. y, posteriormente, da click sobre la
unica opcion
que aparece en la parte superior: Agregar
un campo MARC para este tipo
de materiales (book). Como se muestra
en la siguiente figura:
4. Esta opcion permite el poder agregar
los campos
faltantes, esquematizados con antelacion en la Tabla 3. Por ejemplo, si
faltase el campo con la etiqueta 505, simplemente lo agregamos, al
igual que el subcampo correspondiente y su descripcion. Es posible
indicar, tambin, si dicho campo es requerido o no. Esto es importante,
ya que si se indica que si es requerido (true), el sistema mostrara que
es un campo obligatorio. En este caso particular, dicho campo no es
obligatorio, por lo que se senala FALSE.
Por ultimo, el tipo de
control, que consta del campo de texto para unas cuantas palabras o la
otra opcion llamada area de texto, que se utiliza para escribir mucha
mas palabras que la anterior opcion (Figura 12).
Para realizar la carga de datos, se selecciona Subir datos Marc dentro
del menu Catalogacion. Con el fin de verificar los registros, se puede
realizar una carga de prueba, para lo cual se debera marcar la casilla
Verdadero.
Si se desea realizar
la carga final, se debe marcar la
casilla Falso.
Para la entrada
de datos, se debe seleccionar el archivo
openbiblio.mrc generado en el punto anterior por MarcEdit y que se
encuentra en la carpeta WORK de WinIsis
(c:\winisis\work\openbiblio.mrc). Se selecciona la codificacion de
caracteres (UTF-8 es la codificacion para espanol), el tipo de la
coleccion donde se ubicara el material, el tipo de material (book) y si
se desea que los registros puedan ser visualizados en el catalogo en
linea del sistema (Opac).
Al
finalizar esta opcion se da click sobre el
boton Cargar Archivo
Almacenado
(Figura 13).
Si se realizo la carga de prueba, se visualizaran los registros para
realizar una verificacion del archivo MRC, tal y como lo muestra la
siguiente figura. De esta forma es posible realizar cambios sobre el
mismo antes de efectuar la carga final (Figura 14).

Una vez realizado el procedimiento nuevamente marcando la casilla
Falso, se cargaran los datos en la base de datos del sistema de forma
definitiva. Finalizado el proceso, el sistema enviara un mensaje con
los datos tcnicos del archivo almacenado similar al siguiente:
This data is not unicoded
string &
would be converted.
Technical information:
Detected encoding: SJIS
Conversion: UTF-8 > UTF-8
Registros transferidos: 34
Technical information:
Detected encoding: SJIS
Conversion: UTF-8 > UTF-8
Registros transferidos: 34
Ahora es posible realizar busquedas, ediciones, controles de copias y demas sobre los registros almacenados desde el EspaBiblio.
Es importante indicar que siempre sera necesario realizar una revision
minuciosa de cada uno de los registros transferidos, a fin de limpiar
cualquier otra inconsistencia que se haya producido durante el proceso
de migracion.
3. CONCLUSION
Las unidades de informacion deben ir a la vanguardia en la tecnologia de almacenamiento y recuperacion de la informacion. El uso de formatos de intercambio de informacion ha permitido la transferencia de datos entre ellas y la migracion a nuevas y mas modernas plataformas. Asimismo, contar con un usuario mucho mas alfabetizado tecnologicamente implica que se deben ofrecer servicios de alta calidad sobre sistemas de automatizacion cada vez mas sofisticados.
La migracion hacia dichos sistemas es imperante. Sin embargo, es importante tener en cuenta que siempre existira prdida de informacion, sobre todo, si es necesario el migrar no solamente de sistema, sino tambin de formato. Como se menciono, el estandar que actualmente se utiliza de manera extendida por los nuevos sistemas de automatizacion es el MARC, por lo que es necesario establecer un plan de migracion procurando transferir la mayor cantidad de campos y con la menor prdida posible.
Por otra parte, el proceso de limpieza de la informacion posterior debe realizarse con sumo cuidado y esmero, a fin de garantizar hasta donde sea posible, la pureza de los datos iniciales. Es importante realizar un estudio previo, con base en la integridad de la base de datos fuente, que determine el posible nivel de inconsistencias que podrian surgir en el proceso. Debido a la cantidad de inconsistencias y prdida de informacion, cabe la posibilidad de que dicho estudio muestre que el proceso de depuracion seria mas costoso que ingresar de forma manual todos los datos en el nuevo sistema.
Por lo tanto, este documento pretende ser una guia con los elementos basicos para realizar una migracion de datos de manera exitosa. Sin embargo, todo el proceso de migracion debe responder a un proyecto de automatizacion o de migracion de datos previamente disenado.
3. CONCLUSION
Las unidades de informacion deben ir a la vanguardia en la tecnologia de almacenamiento y recuperacion de la informacion. El uso de formatos de intercambio de informacion ha permitido la transferencia de datos entre ellas y la migracion a nuevas y mas modernas plataformas. Asimismo, contar con un usuario mucho mas alfabetizado tecnologicamente implica que se deben ofrecer servicios de alta calidad sobre sistemas de automatizacion cada vez mas sofisticados.
La migracion hacia dichos sistemas es imperante. Sin embargo, es importante tener en cuenta que siempre existira prdida de informacion, sobre todo, si es necesario el migrar no solamente de sistema, sino tambin de formato. Como se menciono, el estandar que actualmente se utiliza de manera extendida por los nuevos sistemas de automatizacion es el MARC, por lo que es necesario establecer un plan de migracion procurando transferir la mayor cantidad de campos y con la menor prdida posible.
Por otra parte, el proceso de limpieza de la informacion posterior debe realizarse con sumo cuidado y esmero, a fin de garantizar hasta donde sea posible, la pureza de los datos iniciales. Es importante realizar un estudio previo, con base en la integridad de la base de datos fuente, que determine el posible nivel de inconsistencias que podrian surgir en el proceso. Debido a la cantidad de inconsistencias y prdida de informacion, cabe la posibilidad de que dicho estudio muestre que el proceso de depuracion seria mas costoso que ingresar de forma manual todos los datos en el nuevo sistema.
Por lo tanto, este documento pretende ser una guia con los elementos basicos para realizar una migracion de datos de manera exitosa. Sin embargo, todo el proceso de migracion debe responder a un proyecto de automatizacion o de migracion de datos previamente disenado.
4. REFERENCIAS
Bermudez, Y. (2013). Migracion de datos de WinIsis a OpenBiblio. San Jos, Costa Rica: EBCI.
Biblioteca del Congreso de los Estados Unidos. (2003). Qu es un registro MARC, y porqu es importante? Recuperado de http://www.loc.gov/marc/umbspa/um01a06.html
Chinchilla, R. (2011). El software libre: una opcion para la automatizacion de de unidades de informacion. Bibliotecas, 29(2). Recuperado de http://eprints.rclis.org/19389/1/1557-3836-1-SM.pdf
Chinchilla, R. y Fernandez, M. (2012). Bibliotecas automatizadas con software libre: establecimiento de niveles de automatizacion y clasificacion de las aplicaciones. Bibliotecas, 30(2). Recuperado de http://eprints.rclis.org/19390/1/4912-10390-1-SM.pdf
Fernandez, M. (2013). Clasificacion del software libre orientado a la automatizacion integral de bibliotecas segun el nivel de complejidad de la biblioteca: bibliotecas simples, bibliotecas de mediana complejidad y bibliotecas de alta complejidad. E-Ciencias de la Informacion, 3(1). Recuperado de http://revistas.ucr.ac.cr/index.php/eciencias/article/view/8491/0
Furrie, B. (2001). Conociendo MARC bibliografico: catalogacion legible por maquina. Washington: Biblioteca del Congreso de los Estados Unidos.
Ugonono, M. (2011). Cronologia del CDS/ISIS. Boletin electronico ABGRA, 3(3).
United Nations Educational, Scientific and Cultural Organization [Organizacion de las Naciones Unidas para la Educacion, la Ciencia y la Cultura, UNESCO]. (2003). WinIsis: manual de referencia [Version 1.5]. Madrid: CINDOC-CSIC
United Nations Educational, Scientific and Cultural Organization [Organizacion de las Naciones Unidas para la Educacion, la Ciencia y la Cultura, UNESCO]. (2010). CDS/ISIS database software: UNESCO and Information processing tools.http://portal.unesco.org/ci/en/ev.php-URL_ID=5330&URL_DO=DO_TOPIC&URL_SECTION=201.html
Vera, C. (2003). Sistema de Informacion Bibliografica de la CEPAL: manual de referencia. Santiago de Chile: CEPAL Recuperado de

Metodologia
para la migracion de datos bibliograficos entre programas de software de
automatizacion: de CEPAL a MARC
by Jos Ivan Saborio-Acuna y
Ricardo Chinchilla-Arley is licensed under a Creative
Commons Reconocimiento-NoComercial-CompartirIgual 4.0 Internacional
License.
[1]
Universidad de Costa Rica, Escuela
de Bibliotecologia y
C.I. JOSE.SABORIOACUNA@ucr.ac.cr
[2] Universidad de Costa Rica, Escuela de Bibliotecologia y C.I. RICARDO.CHINCHILLA@ucr.ac.cr
[2] Universidad de Costa Rica, Escuela de Bibliotecologia y C.I. RICARDO.CHINCHILLA@ucr.ac.cr
[3] http://reddes.bvsaude.org/projects/abcd
[4] http://sourceforge.net/projects/espabiblio/
[5] http://marcedit.reeset.net/
[6] ISO 2709 es el estandar de la International Standar Organizaction para la descripcion bibliografica. Para mayor informacion consultar http://es.wikipedia.org/wiki/ISO_2709
[7] Para una lista completa de los campos del formato CEPAL se puede consultar el documento Vera, C (2003) Sistema de Informacion Bibliografica de la CEPAL: manual de referencia. Santiago de Chile: CEPAL.
[8] La aplicacion puede ser descargada de forma libre en http://marcedit.reeset.net/downloads
[9] EspaBiblio es software libre (GNU General Public License) basada en OpenBiblio y puede descargar la aplicacion en http://sourceforge.net/projects/espabiblio/